For high-transaction applications with complex architectures, continuous data exchange can cause a non-uniform load and delay in throughput. As such, data refinement is a significant challenge in large and complex business applications. To address this, stream processing is used to define a particular data flow by creating data streams. A typical stream application consists of several producers generating new events and a set of consumers processing these events.
Key Takeaways
Server-Side Filtering: NCache Continuous Query (CQ) offloads data filtration from the client to the server-side, reducing application complexity and network overhead.
Persistent Data Streams: Unlike traditional Pub/Sub models that delete messages after delivery, CQ preserves data in the cache to ensure no data loss for future subscribers.
Decoupled Architecture: Multiple applications can independently monitor specific data subsets (e.g., Gold vs. Silver customers) using SQL criteria without creating inter-service dependencies.
Optimized Notifications: Use of EventDataFilter allows applications to receive only cache keys instead of full objects, significantly minimizing payload size during high-transaction periods.
One popular application is Pub/Sub, where publishers send messages and subscribers receive the messages they are subscribed to. However, in stream processing, traditional Pub/Sub implementations face some limitations. Once a subscriber receives a message, the application no longer retains it. Therefore, if another subscriber later wants messages from the publisher, the previous messages no longer exist. Moreover, for incoming stream data, data filtration occurs at the client-end (subscriber) rather than the server, which makes the application architecture more complex.
To overcome these limitations of traditional Pub/Sub models, NCache provides an efficient mechanism for processing data on the server-side using Continuous Queries. This feature allows applications to receive notifications regarding any changes occurring in the cached data that meet certain criteria. This blog explains the advantages of using Continuous Queries in stream processing, with a solution provided on GitHub.
| Feature | Traditional Pub/Sub | NCache Continuous Query |
|---|---|---|
| Data Persistence | Messages removed after delivery | Data remains in cache for future subscribers |
| Filtering Location | Client-side (Subscriber) | Server-side (Cache Cluster) |
| Network Overhead | High (sends unfiltered data) | Low (sends only matched data) |
| Decoupling | Tight coupling with message bus | Complete decoupling via SQL criteria |
Using Continuous Query for Stream Processing
Imagine you have an e-commerce application that processes thousands of customers daily for their online purchases. In the diagram below, customers of various types and categories are added to the application. To make customer processing more efficient, these unfiltered customers are categorized and filtered into “Gold,” “Silver,” and “Bronze” categories based on the number of their orders, using Continuous Queries.
A Continuous Query allows applications to receive notifications when data meeting certain criteria changes inside the cache. The criteria is specified using SQL commands. For example, if an application wants to tag customers with a higher number of orders as ‘Gold Customers,’ it simply needs to register an SQL command with the criteria, thereby providing a callback. This callback is triggered whenever a change occurs in the result set that fulfills the criteria. Once the callback is invoked, the application can categorize these customers as “Gold Customers” using tags.
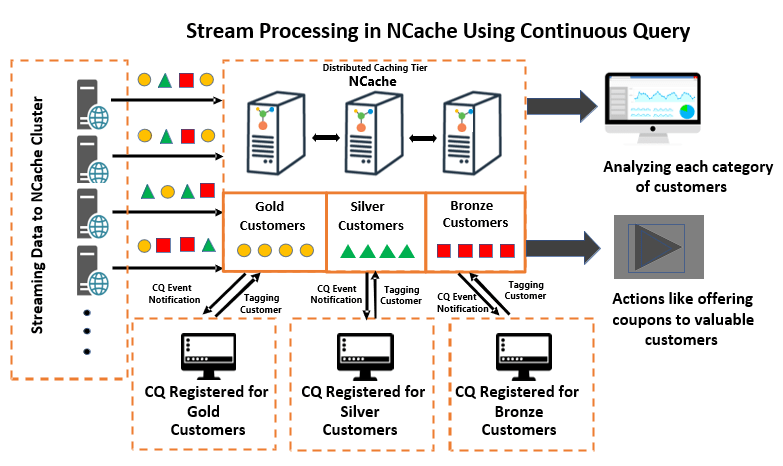
Figure 1: High-Performance NCache CQ Architecture for Real-Time Streaming
Similarly, the application can create multiple categories by registering multiple Continuous Queries, each with its own criteria and callback. This approach ensures that the application only receives the filtered data it is interested in. The filtered data can then be further analyzed according to business requirements, such as providing discounts to high-end customers based on their category.
Implementing Continuous Query
Events are triggered if any of the following data modification actions take place in the cache:
- Add: Adding a new item to the cache that fulfills the query criteria.
- Update: Updating an existing item in the query result set.
- Remove: Removing an item from the cache or updating an existing cached item so that it causes the item to be removed from the query result set.
So, to implement this, you will first have to register an event call backs, as detailed below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
public void OnChangeInQueryResultSet(string key, CQEventArg arg) { switch (arg.EventType) { case EventType.ItemAdded: Console.WriteLine($"Item with key '{key}' has been added to result set of continuous query"); break; case EventType.ItemUpdated: Console.WriteLine($"Item with key '{key}' has been updated in the resut set of continuous query"); // Get updated Product object // Item can be used if EventDataFilter is DataWithMetadata or Metadata if (arg.Item != null) { Product updatedProduct = arg.Item.GetValue(); Console.WriteLine($"Updated product '{updatedProduct.ProductName}' with key '{key}' has ID '{updatedProduct.ProductID}'"); } break; case EventType.ItemRemoved: Console.WriteLine($"Item with key '{key}' has been removed from resut set of continuous query"); break; } } |
Then a query and notifications, as demonstrated below. The following code example uses stream processing in the cache with a Continuous Query. In this example, a Continuous Query is executed on the data where orders greater than 10 are added to the “Gold Customers” category. Moreover, an event is triggered for every item added to the query result set. The data is then returned based on the established EventDataFilter’s.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
string query = “SELECT $VALUE$ FROM Models.Customer WHERE OrdersCount >= ?”; var queryCommand = new QueryCommand (query); queryCommand.Parameters.Add("OrdersCount", 10); var contQuery = new ContinuousQuery(queryCommand); // EventDataFilter.None returns the cache keys added cQuery.RegisterNotification(new QueryDataNotificationCallback (QueryItemCallBackForGoldCustomers), EventType.ItemAdded, EventDataFilter.None); cache.MessagingService.RegisterCQ(contQuery); // Register callback for event notifications in the result set |
Key Implementation Logic:
- QueryCommand: Uses standard SQL syntax to offload filtering logic from your application to the server.
- EventType.ItemAdded: Minimizes noise by only triggering notifications when new data enters the “Gold” category.
- EventDataFilter.None: Optimizes performance by returning only the Key, reducing the payload size across the network.
Preserving Data with CQ
Now, the data filtered through the Continuous Query (for customers with orders >10) is tagged as “Gold Customers” and updated in the cache. Look at the code below to see how it’s done.
|
1 2 3 4 5 6 7 8 9 10 11 |
// A callback for previously executed query private void QueryItemCallBackForGoldCustomers (string key, CQEventArg arg) { var cacheItem = _cache.GetCacheItem(key); cacheItem.Expiration = new Expiration(ExpirationType.Sliding, TimeSpan.FromMinutes(5)); Tag[] tags = new Tag[1]; tags[0] = new Tag("GoldCustomers"); cacheItem.Tags = tags; cache.Insert(key, cacheItem); } |
A Continuous Query keeps data preserved in the cache even after processing. This solves the problem faced with Pub/Sub in scenarios with continuously emerging data, where multiple applications publish data into the NCache messaging layer. In such cases, multiple subscribers receive the data, but there is no reliable data storage, as messages are removed from the message bus once they are received. Typically, the data would need to be stored by the application or by adding a new data source, which is a far more complex scenario. Continuous Queries, on the other hand, ensure that there is no data loss, thus saving you the extra effort of manually persisting your data.
Decoupling Applications with Continuous Queries through Powerful Filtration
Large, complex applications can have various groupings based on their architectures. For example, running out of 10 running applications, two might be dealing with the Gold customers’ dataset, while another two handle the Silver customers’ dataset. In such cases, you would want separate business logic for each dataset, where data is filtered according to each application’s needs for stream processing. Therefore, such applications require decoupling, as interdependencies between applications can lead to significant performance bottlenecks and increased complexity.
Continuous Queries efficiently filter your applications’ data using sophisticated SQL statements, ensuring each application operates independently without overlap. This decoupling is especially beneficial in a microservices architecture, where each service runs on a separate application stack and processes its own data without creating dependencies. This level of data filtration and application decoupling cannot be achieved using Pub/Sub. Figure 2 shows various client applications dealing with their respective datasets in a decoupled architecture using NCache Continuous Queries.
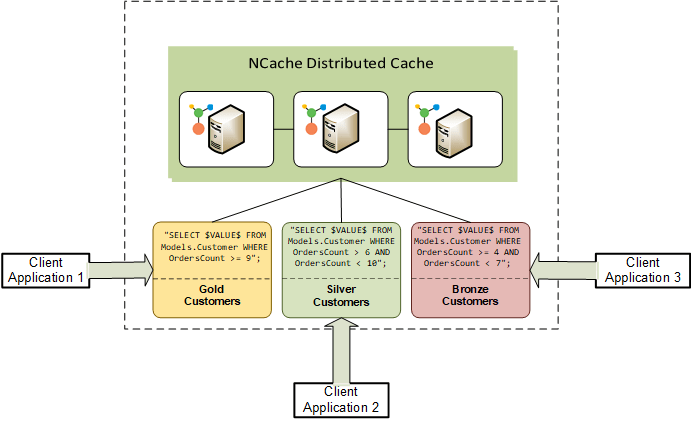
Figure 2: Application Decoupling using NCache Server-Side SQL Filtering
Fetching Data Using Tags
Tags in NCache act as additional qualifiers for categorizing data. For large data sets such as the scenario mentioned, tags are really useful for fetching relevant data instead of searching the whole cache for the data. If a customer falls under the category of “Gold Customers”, a tag is added with it for quick retrieval. Based on these categories, the customers can be provided added with benefits such as discounts, coupons, etc. NCache provides various flexible ways for fetching data using tags, as explained thoroughly in the documentation. Now let us look at the code on how to retrieve “Gold Customers”, i.e., customers who can be offered coupons or premium services.
|
1 2 3 4 5 6 7 8 9 10 11 |
string key = $"Customers:{customer.CustomerID}"; var cacheItem = new CacheItem (customer); Tag[] tags = new Tag[2]; tags[0] = new Tag ("Gold Customers");] cacheItem.Tags = tags; CacheItemVersion version = cache.Insert(key, cacheItem); // Retrieve the cache items with the tag for processing ICollection retrievedKeys = cache.SearchService.GetKeysByTag(tags[0]); |
Expiring Cache Data
NCache allows cache data expiration that invalidates the data after a specific interval and then removes it from the cache at a clean interval.
NCache provides two types of expirations:
In case of customers, expiration is added with a 5 minute sliding expiration interval.
|
1 2 3 4 |
var cacheItem = new CacheItem(customers[0]); // Set Expiration TimeSpan cacheItem.Expiration = new Expiration(ExpirationType.Sliding, TimeSpan.FromMinutes(5)); cache.Insert("CustomerID:" + customers[0].Id, cacheItem); |
Conclusion
In conclusion, NCache’s Continuous Query feature offers a robust solution for stream processing in complex applications by efficiently filtering and preserving data within the cache. Unlike traditional Pub/Sub implementations, Continuous Queries ensure that critical data is retained, allowing for more streamlined processing and decoupling of applications. This approach not only enhances performance but also simplifies the architecture. Additionally, by leveraging tags and flexible expiration policies, NCache enables precise data retrieval and management, ensuring that your applications can handle high-transaction scenarios with ease.
Frequently Asked Questions (FAQ)
Q: What specific cache actions trigger a Continuous Query notification?
A: Notifications are triggered by three specific events: Add (a new item matches the criteria), Update (an existing item is modified to match or changes within the result set), and Remove (an item is deleted or modified so it no longer meets the criteria).
Q: How does NCache use SQL for stream processing?
A: NCache uses a SQL-like syntax (OQL) to define datasets. For example, you can register a query such as SELECT $VALUE$ FROM Models.Customer WHERE OrdersCount >= 10 to automatically monitor and categorize data streams in real-time.
Q: Can I categorize data using more than just Continuous Query?
A: Yes. The article demonstrates that once a Continuous Query filters the data, you can use NCache Tags to logically group items (like “Gold Customers”). This allows for high-speed retrieval using GetKeysByTag without re-scanning the entire cache.
Q: What is the difference between Absolute and Sliding Expiration in this context?
A: The article suggests using Sliding Expiration (e.g., 5 minutes) for streaming data like customer sessions. This keeps the data alive as long as it is being accessed, whereas Absolute Expiration would remove the data at a fixed time regardless of activity.
Q: How do I handle the actual data change once a notification is received?
A: You must implement a QueryDataNotificationCallback. This method receives a CQEventArg containing the event type and the item’s key, allowing your application to execute logic like applying discounts or updating tags immediately.