Distributed Lucene for Scalable Full Text Search
Apache Lucene is very popular free open source full text search engine originally written in Java but also ported to .NET. Lucene is a stand-alone library that applications embed in order to perform full text searching.
NCache has implemented Lucene API in .NET in its native form over its In-Memory Distributed Cache (hence the name Distributed Lucene). This has transformed the stand-alone Lucene into an extremely fast and linearly scalable full-text searching solution for .NET / .NET Core applications. And, due to the native Lucene API, you don’t have to make any code changes to your .NET Lucene applications in order to use it with NCache.
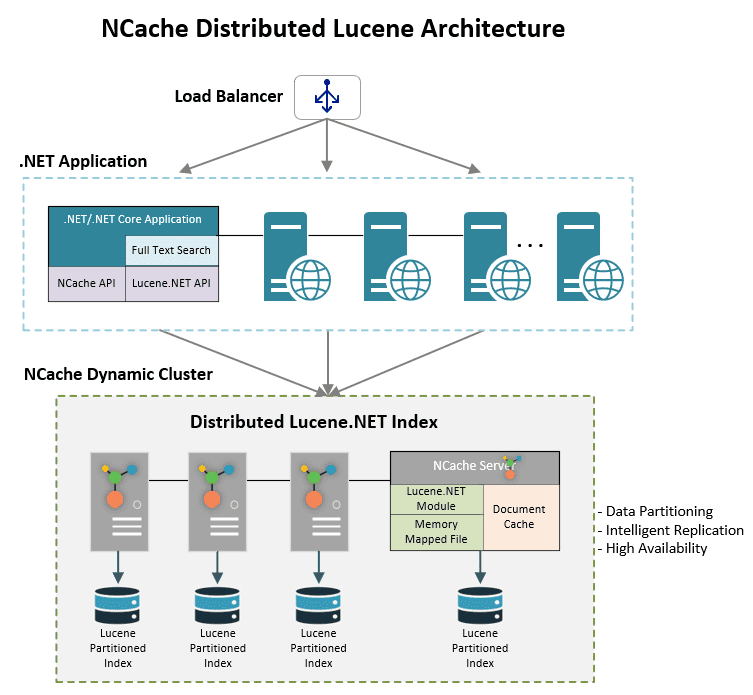
On the client end, NCache provides your .NET application the native Lucene.NET API so you don’t have to change any code in your application. And, on the back-end, NCache uses the same Lucene.NET to build indexes in a distributed environment and later to conduct full-text searches in a distributed manner. The results of these distributed searches are then merged before being presented to your application.
Native Lucene API
Distributed Lucene with NCache provides you a native Lucene API. As a result, you get the following benefits from it:
- - No Code Change: you don’t have to make any code changes to your Lucene application in order to use Distributed Lucene. Just change your provider to NCache.
- - Industry Standard API: by using Lucene in your application, you’re sticking to industry’s most popular full text searching API.
Extremely Fast & Linearly Scalable
Distributed Lucene is extreme fast and scalable for the following reasons:
- - In-Memory (Fast): Distributed Lucene is built on top of NCache that is an In-Memory Distributed Datastore. As a result, Distributed Lucene is also in-memory and therefore very fast.
- - Lucene Index Partitioned: in order to provide scalability, Lucene index is partitioned across all the servers in the cluster. This way, as you add more servers to the cluster, Lucene index is automatically repartitioned and redistributed in an intelligent manner by using NCache Partition-Replica Cache topology.
- - Parallel Searches: since Lucene index is partitioned, when your application issues a full text search query, Distributed Lucene sends it to all the servers in the cluster. And, this way, your query runs in parallel across multiple servers. Then, results from all those parallel queries are merged before returning to your application.
- - Add/Remove Servers from Cluster at Runtime: you can add more servers to NCache cluster at runtime without stopping your application or rebuilding your Lucene index. Lucene index is automatically redistributed to all the servers in the cluster without any interruptions.
- - Grow Lucene Index at Runtime you can add more items to the Lucene index at runtime without stopping or rebuilding the entire Lucene index.
High Availability
Here are some highlights of Distributed Lucene in this area:
- - Lucene Index Replicated: Lucene index is partitioned across all the servers in the cluster. And, then each partition is replicated to a different server in the cluster by using Partition-Replica Cache topology in NCache. This ensures high availability so if any server goes down, the replica of this partition is automatically available without any interruptions.
- - NCache Cluster is Dynamic: the dynamic nature of this cluster means that if any one server goes down, the cluster automatically adjusts itself to work with one less server. And, all of this happens without any interruptions. Similarly, if you need to grow the number of servers at runtime, the cluster automatically adds it to the cluster without any interruptions.
- - Persist/Reload Lucene Index: you can persist the entire Lucene index to the disk. This way, if you need to bring down the entire NCache cluster for maintenance, you can quickly restart it and reload the entire Lucene index without any custom programming.
- - Auto-Load Lucene Index: Use CacheLoader feature of NCache to write your custom code to load documents or data from your data source and build index upon startup of the Cluster.