In this era of fast and reliable application processing, everybody is opting for distributed caching to get the best performance out of their application. If your web applications attract high traffic causing extremely high transactions, then you definitely need NCache.
NCache is an in-memory distributed caching solution that provides linear scalability to .NET and Java applications. Among various topologies that NCache provides you, the most popular is Partitioned-Replica topology. Partitioned-Replica topology gives you the best of both worlds, linear scalability, and high availability.
In the Partitioned-Replica cluster, data is partitioned as well as replicated on all the nodes. Hence, if a server node goes down, its clients can continue with their operations by interacting with its replica counterpart. As soon as a node goes down, the state transfer process is triggered to auto-rebalance the orphaned data. Now assume that you have a Partitioned-Replica cluster, and you require one of the nodes to be stopped for maintenance while knowing that you will be restarting that node not that long after? Let us see what this behavior is and how it could be a challenge for you.
NCache Details Partitioned-Replica NCache Docs Maintenance Mode NCache Docs
Auto-Rebalancing Challenges During Maintenance
Every time a node is stopped in a Partitioned-Replica cluster; state transfer is triggered to rebalance the data throughout the cluster. This process can take more time than anticipated, which affects your application’s performance, especially when the nodes hold tens of gigabytes of data.
The following figure explains the behavior of the Partitioned-Replica cluster when a node is stopped.
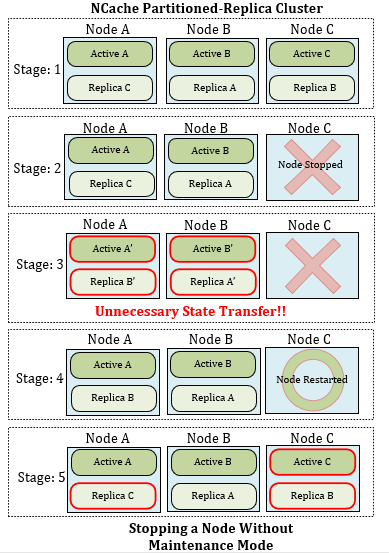
Figure1: Stopping a node without Maintenance Mode
In this figure, you have an NCache Partitioned-Replica cluster with three nodes. Here, five stages have been introduced to explain what happens when a node is stopped in a cluster.
- Stage 1: NCache’s Partitioned-Replica with three nodes, A, B, and C, each having an active and a replica node.
- Stage 2: Node C is briefly stopped for Maintenance. Its active and replica are not a part of the cluster anymore and state transfer is triggered.
- Stage 3: Data redistribution in the cluster (totally unnecessary). Here, orphaned data of node C is divided between the remaining nodes A & B after state transfer has stopped. According to this division, their replica nodes are updated too. This state transfer is totally unnecessary because the stopped node will be restarting soon.
- Stage 4: Node C restarts. The cluster, at this stage, behaves as if node C has left the cluster. After data redistribution, Node C is started again.
- Stage 5: Node C rejoins the cluster and again does data redistribution. As its data had already been distributed between A and B, hence when C rejoins, state transfer is triggered throughout the cluster again to assign new data to the nodes.
Ideally, this seems like the perfect solution. You stop a node, state transfer occurs. You fix whatever you wanted to fix and start that node again. State transfer is again triggered to balance all buckets.
But why isn’t this the ideal solution? What goes wrong here?
There are several drawbacks of prompting state transfer unnecessarily. They are:
- High cost due to multiple network calls and processing overhead.
- High time complexity when the nodes hold a large amount of data.
- Erroneous behavior when a node restarts during state transfer and leads to state transfer within state transfer.
NCache Details Partitioned-Replica NCache Docs Maintenance Mode-NCache Docs
The Solution: Maintenance Mode Aware Partitioned-Replica
Taking into consideration all these setbacks of unnecessary state transfer that occurs whenever a node leaves and joins a cluster, NCache provides you with Maintenance Mode.
Maintenance Mode allows you to stop a node for a specific period and start it when its maintenance is over. This mode ensures that during the time that a node is going through maintenance, the state transfer thread is not triggered within the cluster. Also, it is extremely beneficial where the cluster comprises a large amount of data.
How Maintenance Mode is different from the normal stopping of a node, is explained in the following figure.
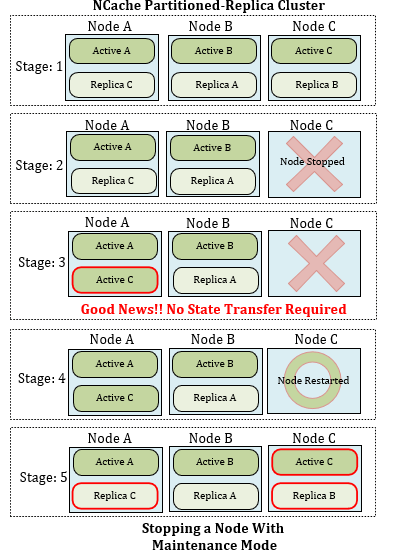
Figure2: Stopping a node without Maintenance Mode
- Stage 1: The structure of the Partitioned-Replica topology of NCache is shown where a POR cluster comprises three server nodes that contain a huge amount of data.
- Stage 2: Node C stopped. Node C is stopped for maintenance through Maintenance Mode.
- Stage 3: Data redistribution. Here, the replica of C becomes active and starts addressing node C’s clients. This eliminates the need to trigger state transfer, hence, the state transfer thread is halted for as long as the cluster is under maintenance. This solves the problem faced when unnecessary state transfer balances the data across the cluster after node C is stopped.
- Stage 4: Node C restarted. After being stopped for maintenance purposes, node C waits to be restarted. Whenever the cluster exits Maintenance Mode, Node C starts.
- Stage 5: Data transfer. It is that phase of the cluster where Node C receives all data from its replica part and updates the entire node (i-e Active C and Replica B) through state transfer.
NCache Details Partitioned-Replica NCache Docs Maintenance Mode-NCache Docs
How to stop a node for maintenance
You can stop a node for maintenance either using Web Manager or PowerShell. Here is how you can stop a node for maintenance from your Web Manager. On stopping a node, you are asked to mention the maintenance time for which you want to keep that node under maintenance. This timeout is considered as a period for which no state transfer can be triggered.
The following steps allow you to stop whichever node you want to stop for maintenance.
- Access your NCache Web Manager
- Go to Clustered Caches and select the cluster that needs maintenance
- Among its various nodes, select the one that requires maintenance.
Go to its settings and select the option Stop for Maintenance.
How to exit a node from Maintenance Mode
Once a cluster enters Maintenance Mode, the Web Manager is used to exit that cluster from it. Following are the steps that need to be followed:
- From your NCache Web Manager, go to Clustered Caches
- Select the cluster that is under maintenance.
- Go to its Settings and select Exit Maintenance Mode.
Other than from the Web Manager, there are several ways through which a node can exit from maintenance mode. These scenarios need to be taken into consideration as some might affect your application’s performance.
A node can exit Maintenance Mode in the following cases:
- When the node under maintenance is started: If the node that is under maintenance is started manually, either through the manager or through the PowerShell command, that node exits Maintenance Mode.
- When the timeout expires: When the timeout provided for maintenance expires, state transfer is triggered and the cluster automatically exits Maintenance Mode.
- When a node leaves the cluster: No node can leave a cluster gracefully as long as it is under maintenance. But if one of the nodes of that cluster leaves forcefully, that cluster inevitably falls out of Maintenance Mode, despite still being under the maintenance process. Here, the point that you should pay attention to is that if the very node that was under maintenance leaves, there are high chances of data loss.
No matter which method you use to exit Maintenance Mode, that signal alone is the cue for the state transfer thread to trigger the auto-balancing process throughout the cluster.
Summing up
If you desire a way to accommodate patching in your Partitioned-Replica clustered cache without compromising the application’s performance, then check out NCache Maintenance Mode. Maintenance Mode allows you to fix a bug, add a patch, upgrade software or hardware, without introducing any application downtime. All you have to do is follow the above-mentioned steps and check out for yourself how extraordinary NCache Maintenance Mode is.