Peak loads, failures, system outages are highly likely to be a part of your cache cluster and it is not something to be worried about. However, having no workaround to such situations definitely is! Fault resilience against such risk causing factors is the primary requirement of your caching cluster so that recovering from failure scenarios is always handy. In some situations, data loss can be negligible and can be dealt with easily but in some cases where mission-critical data is involved, data protection and availability cannot be put as a secondary requirement.
NCache Does NOT Lose Your Data!
NCache, being an in-memory distributed data caching store, provides an architecture where high availability of data is ensured under peak loads or downtime. Your data remains 100% available even in disastrous situations like a node permanently leaving the cluster. NCache is architected to deal with runtime addition or removal of a server node.
You can also modify cache configurations at runtime with the hot applicable features. With the peer to peer architecture, NCache saves you with the biggest problem of “single point of failure”. The failover support is not just provided within the cache cluster but also with the clients connected to the cache. It makes NCache highly dynamic and extremely confident to claim no data loss. Let us look at the figure below to understand NCache’s availability.
Step 1 shows a connected cluster where clients are connected with the NCache cluster having peer to peer architecture.
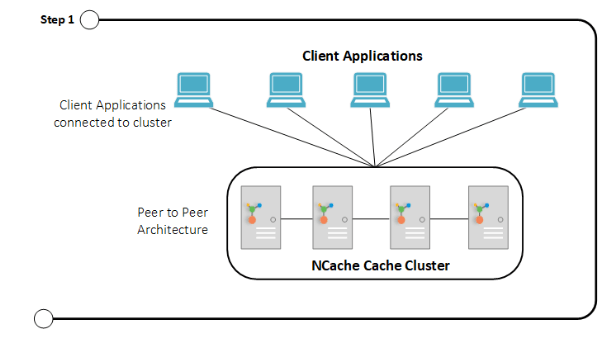
Step 1: Clients Connected to NCache
Figure 2 shows a node leaving the cache cluster due to any disaster.
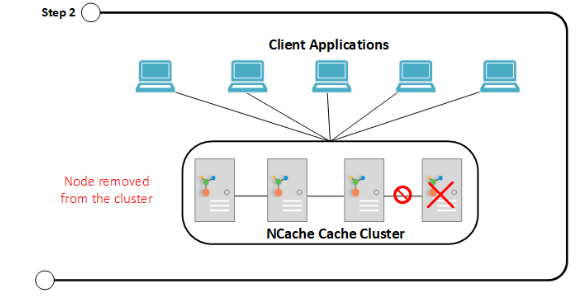
Step 2: Server node removed
The figure below shows that the cache cluster balanced the data between the remaining nodes and the clients remain connected to the cache cluster.
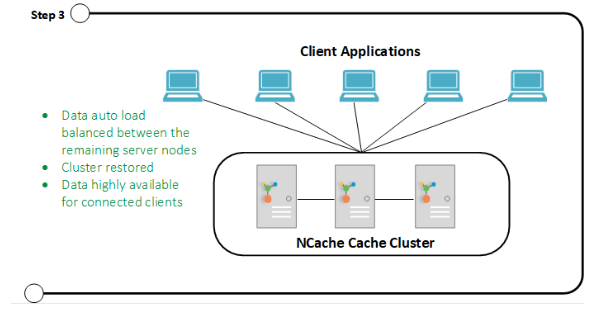
Step 3: Cluster Restored
Caching Topologies
NCache provides different topologies for data storage so you can store the data according to your own requirement. Look at the topologies below:
- Mirrored Topology: As the name suggests, mirrored topology means a cluster with two nodes, one being the active node mirrored with the passive node.
- Replicated Topology: In replicated topology, each node has the same data replicated on it.
- Partitioned Cache: In partitioned topology, every server node has a partition and the data is evenly divided between the node and its partition.
- Partition of Replica Cache: Partition of Replica topology is the fastest topology as it keeps the replica of every partition. Every partition is replicated on a different server and the replicas are passive which means clients cannot connect to them.
Let us now discuss data availability w.r.t. caching topologies. Each topology as mentioned has different characteristics. Replicated topology makes sure that the data is replicated on all nodes thus keeping the data 100% available. In Partitioned Topology, if a single node is down, some portion of the data is lost. However, in Partitioned Replica Topology, as every partition has a replica, if a node is lost, the data is redistributed among the remaining nodes. It makes the POR topology the most efficient with respect to data availability. Asynchronous Partitioned Replica topology has background data replication which may cause data loss, however, with synchronous POR topology no data loss occurs as replication occurs through the client application.
Caching Topologies Self healing dynamic clustering NCache Architecture
Peer to Peer Architecture in NCache
Peer to peer architecture means that there is no concept of master or slave node in NCache. A cluster is formed by a well-defined set of servers and each server is connected to every other server in the cache cluster. There is a coordinator node which is responsible for managing the whole cluster. A coordinator node is the senior most node with respect to the nodes joining the cluster. If a coordinator node leaves the cluster the next senior-most node becomes the coordinator node. The coordinator node also shares the entire information of the data distribution on the other nodes so that the next coordinator node already knows all about data distribution.
The data distribution takes place on the basis of buckets. A single bucket is the minimum unit of data distribution. All the buckets are evenly distributed among the nodes in the cache cluster.
For instance, a cache cluster with two nodes and 1000 buckets of data keeps 500 buckets of data on each node. NCache distributes the data based on a distribution map. The distribution map maps the buckets with the nodes on which the buckets reside.
The process of data being transferred from one node to another node is called state transfer. It transfers the data bucket by bucket from the existing (source node) to the new (assigned) node. The time during which state transfer takes place, all the operations failing/related to a given bucket are directed to the source node until the entire state transfer process has taken place. Once the state transfer process is complete, all the nodes are informed about the state transfer being complete.
Runtime Discovery within Cluster and Clients
NCache excels in data availability for its dynamic features. If a node joins the cache cluster, all the server and client nodes are provided this information at runtime making the data distribution take place. The coordinator node makes sure that a new server has joined the cache cluster and it adds the new server node in the node list of the cache cluster. It also informs all the other server nodes about a new server node entering the cache cluster. After that, the new server node acquires a TCP connection with all the other server nodes. Hence, the new server has no information on the existing cache server nodes until it has joined the cache cluster.
Similarly, the cache clients are also discovered at runtime. A client when connecting to the cache cluster does not need to know about the entire cache cluster and all the server nodes. It only needs the information of a single running cache server. It uses this connection to see which cache severs to connect to. Following is the vital information the client is served after connection establishment:
- Data Distribution Map: The map that holds the information of which data residing on which server node so it can be accessed easily.
- Caching Topology: The information about the cache topology to determine which cache server to connect to.
- Cluster Membership Information: The information about the members of the cluster such as a new node entering the cluster or an existing node leaving a cluster.
- Information regarding compression or encryption.
- Serialization Information: Binary or JSON.
Dynamic Clustering Split Brain Auto Recovery Maintenance Mode
Connection Failover Support
NCache cluster is a dynamic self-healing cluster and deals with any failover at runtime. Two kinds of failover support is provided by NCache:
- Failover Support within Cluster: If a cache server leaves the cluster at any time, the cache cluster very efficiently heals itself from the loss of a cache server. To further explain it, it means that the cache cluster divides the data buckets among the remaining cache server nodes and updates all cache server nodes about the new distribution.
- Failover Support within Client: Similar to cache servers, cache clients also adjust themselves according to the other existing cache servers. If a client is connected to a cache server and the connection is lost due to the unavailability of the server node, all clients connected to it automatically move to other existing nodes.
Maintenance Mode
Maintenance mode is another user-driven feature provided by NCache. As discussed earlier, state transfer takes place on every node leaving or joining the cluster. In scenarios where a server node leaves the cluster to avoid the unnecessary state transfer, maintenance mode comes in handy. It gives you the control to stop a node for maintenance and save your cluster the cost of an expensive state transfer process. While a node is under maintenance, all the operations are served from the replica node. As soon as the node rejoins the cluster, it synchronizes the state with the replica node.
Conclusion
Data availability is the biggest challenge when dealing with cache data. NCache is rich with high-end features to deal with data availability at all costs providing immediate damage control in disastrous situations. Not just that, NCache has a very scalable architecture that provides not just high availability but also lets you scale your cache cluster linearly. So, it is safe to say that NCache is the best caching tier your application architecture needs.





