We all encounter situations where we have to wait for an eternity to get a response from the database in return for the generated queries at the application server. For business-critical applications latency and delay in response are intolerable. This is where a need for an optimized caching solution arises.
While caches are commonly associated with key-value stores, NCache takes it a step further by allowing you to query data on non-key attributes of your objects. This means you can access data based on a wide range of properties beyond just the keys. This approach provides greater flexibility and efficiency for data retrieval, making it easier to analyze and manage your data.
Over time, the data in the cache grows, so you need such capabilities in caches, where you can generate queries for faster search and retrieval performance. NCache enables you to query your data in an efficient manner when you are searching.
How NCache optimizes search and retrieval performance?
NCache optimizes its search and retrieval performance through indexing, projections, chunk size, and client cache. By caching the results of queries in memory request responsiveness is significantly improved. As many queries are served directly from the cache, additional database trips are saved. NCache uses multiple ways to boost search and retrieval performance, as discussed below.
1. Strategically Create Indexes
For efficient data searching based on queries, NCache requires the creation of search indexes. Unlike traditional databases, which can be slow without indexes and perform full store searches to find data, NCache prioritizes performance, making the creation of indexes mandatory. By creating indexes, NCache can determine the data type and storage format that best suit your search needs, ensuring that searches are fast and efficient
However, NCache uses indexing since it is a performance-oriented approach but indexing the attributes for a search must be done very carefully as it requires space to retain an index, and indexing unnecessary attributes can result in memory as well as performance overhead.
NCache provides two ways to define indexes.
• Pre-Defined Index (Static Index)
• Runtime Index (Dynamic Index)
2. Use Projections Smartly
When it comes to queries, projections can significantly improve the performance of your application. Based on your query, NCache enables you to retrieve all the indexed characteristics of a class or particular projections from the cache-store.
Using NCache, you can specify the columns of your choice to be projected against your query to perform the search more efficiently. In addition to specific column projections, you can also retrieve multiple projections. Below mentioned is an example which projects $GROUP$ and $Value$ in a single query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
string query = "SELECT $Value$, $Group$ FROM FQN.Product WHERE Productid > ?"; // Providing parameters for query queryCommand.Parameters.Add("ProductID",50000); // Check if the result set is not empty if (reader.FieldCount > 0) { while (reader. Read()) { Product value = reader.GetValue(1); string group Name = reader.GetValue(2); // Perform operations } } else { // Null query result set retrieved } |
By default, if you don’t specify the projections, then the complete object along with the indexed characteristics travel from server to client upon request – it will be slower than selective data. Below mentioned is an example that retrieves all the fields related to class Product from the cache through the * operator.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
string query = "SELECT * FROM FQN.Product WHERE ProductID > ?"; // Providing parameters for query queryCommand.Parameters.Add("ProductID",50000); // Check if the result set is not empty if (reader.FieldCount > 0) { while (reader.Read()) { string result = reader.GetValue("ProductID"); // Perform operations } } else { // Null query result set retrieved } |
It is important to note that by using projections, NCache reduces the extra work of retrieving all of the indexed characteristics of the object and only retrieves the desired columns. NCache helps users improve performance in this way by facilitating better query syntax.
3. Chunk size / Fetch data in chunks
NCache gives another feature for query optimization called Chunk Size. After executing a search query, the application receives data/key packets in chunks, where each chunk represents a specific size of data/key packets. There are multiple ways to query data, whether you want to query the keys only or selective items, or a complete set of properties of an object – called a dataset.
The bigger the result set, the slower it is to fetch in response to the generated query. So, the client that’s consuming the data instead of fetching the whole result set at once consumes the data in chunks from the server one by one. NCache by default, brings the data in smaller chunks from the server to the client side, merges the data chunks, and gives the data to the application.
The default value of a chunk size is 512 KB but users can configure chunk size based on their requirements, while executing the reader to perform a search on the cache based on the specified query. Since data is traveling in the form of chunks over the network, this improves the performance of search and retrieval of data.
4. Using Client Cache
NCache has a versatile feature called Client Cache (L1 Cache). L1 is a subset of the main cache that resides closer to the application which can be InProc and, OutProc. Since it is a subset of the main cache (L2 Cache), queries do not execute using the L1 Cache. Only key-based operations, like add, get, or getbulk operations execute by searching keys in the L1 cache first, and get missing keys from the L2 cache, merge, and serve.
The L2 cache contains complete data, so queries and operations performed by tags always run on it. Rather than executing a query to retrieve all data from the L2 Cache, the user can get keys only from the L2 Cache. And then use bulk get to retrieve those keys from the L1 Cache. If any data is missing, it will be served from the L2 cache. Frequently performed read/write operations are stored in the client cache, resulting in faster retrieval times for subsequent requests for the same data.
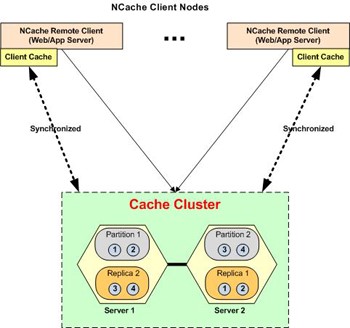
Diagram depicting the working of the Client Cache
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
// Executing query to fetch keys only ICacheReader reader = _cache.SearchService.ExecuteReader(queryCommand, false); // Check if the result set is not empty if (reader.FieldCount > 0) { while (reader.Read()) { //Populate Keys List keys.Add(reader.GetValue(0)); } } //Get Data using Bulk API. IDictionary<string, Product> productsList = _cache.GetBulk(keys); //If the number of keys is very large, you can break the list into multiple chunks and then do GetBulk for each chunk separately. |
NCache provides sample application for fetching data efficiently from Client Cache on GitHub.
Conclusion
In this blog, we covered the multiple ways that NCache uses to enhance its query searching and data retrieval performance. NCache not only boosts application performance but also ensures high availability and scalability to cater to user load. So, without any further wait Download NCache now and start your 60-day free trial!